前言
Puppeteer 是由 Chromium 开源团队开发的一款 Node.js 库,用于通过 Chrome Devtools Protocol(CDP)操作和控制 Chrome 浏览器。在团队实践中,我们通常使用 Puppeteer 来加载页面,进行页面的渲染,在爬取一下客户端渲染(CSR)页面的爬虫场景中极为常用。
由于 Puppeteer 本质是启动一个没有界面、无需人工干预的 Chrome 浏览器(Headless),频繁的启动和关闭 Chrome 进程不仅耗费极大的资源,还需要较长时间,这在大规模页面爬取的场景下性能问题极为明显。同时,Chrome 在启动时本身就是多进程的结构,Crawler Worker 项目使用每个 Worker 都去启动一个 Chrome 无疑会过多的耗费 CPU 和内存资源。
为了缩短使用 Puppeteer 爬取页面的整体时间、解决多个 Worker 各自启动 Chrome 的资源利用率过低的问题,通过调研之后,我们将 Puppeteer 持久化运行。
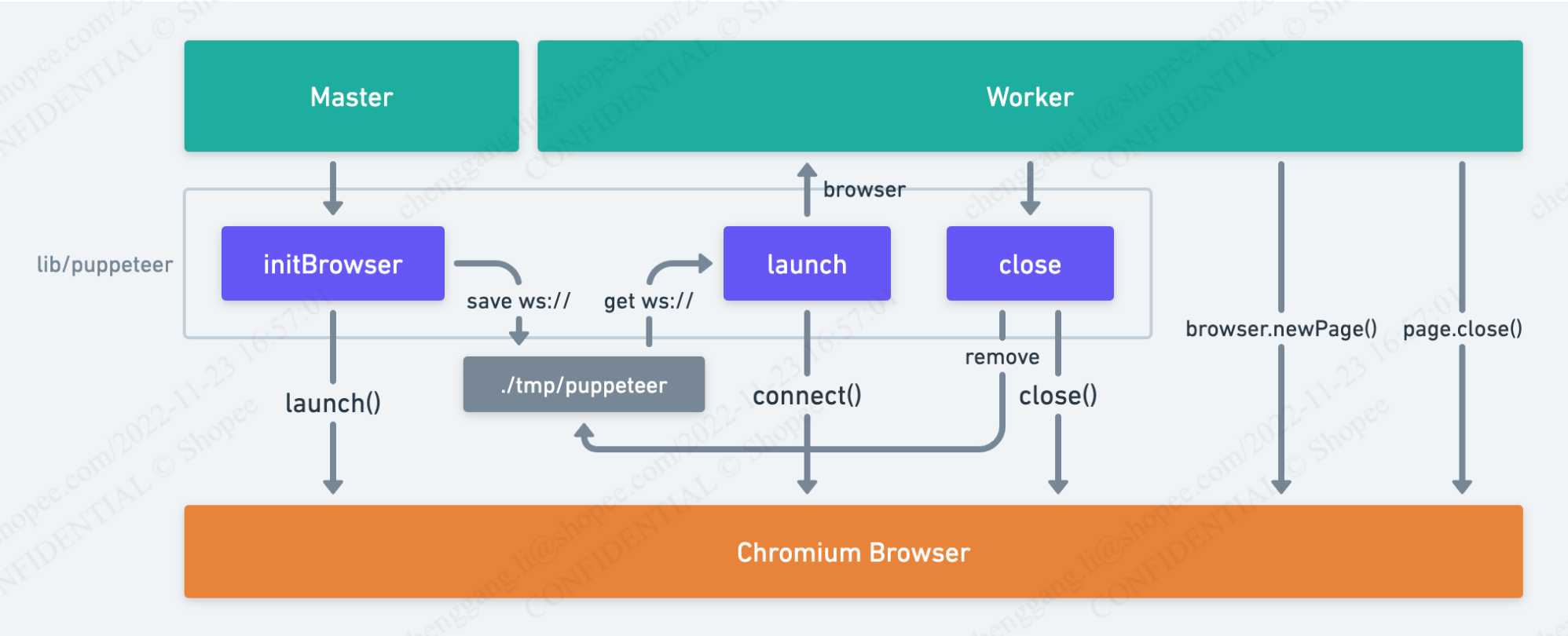
架构图
实现
由于 Puppeteer 本质是启动一个 Chrome 浏览器,然后通过 Chrome Devtools Protocol 接口去控制 Chrome,那么我们可以在 Master 启动的时候,直接启动一个 Chrome 浏览器,并将对应的 Chrome Devtools Protocol 接口地址(称之为 browserWSEndpoint ,实际上是一个 ws:// WebSocket 协议的 URL)读取并保存在 ./tmp/puppeteer 文件中。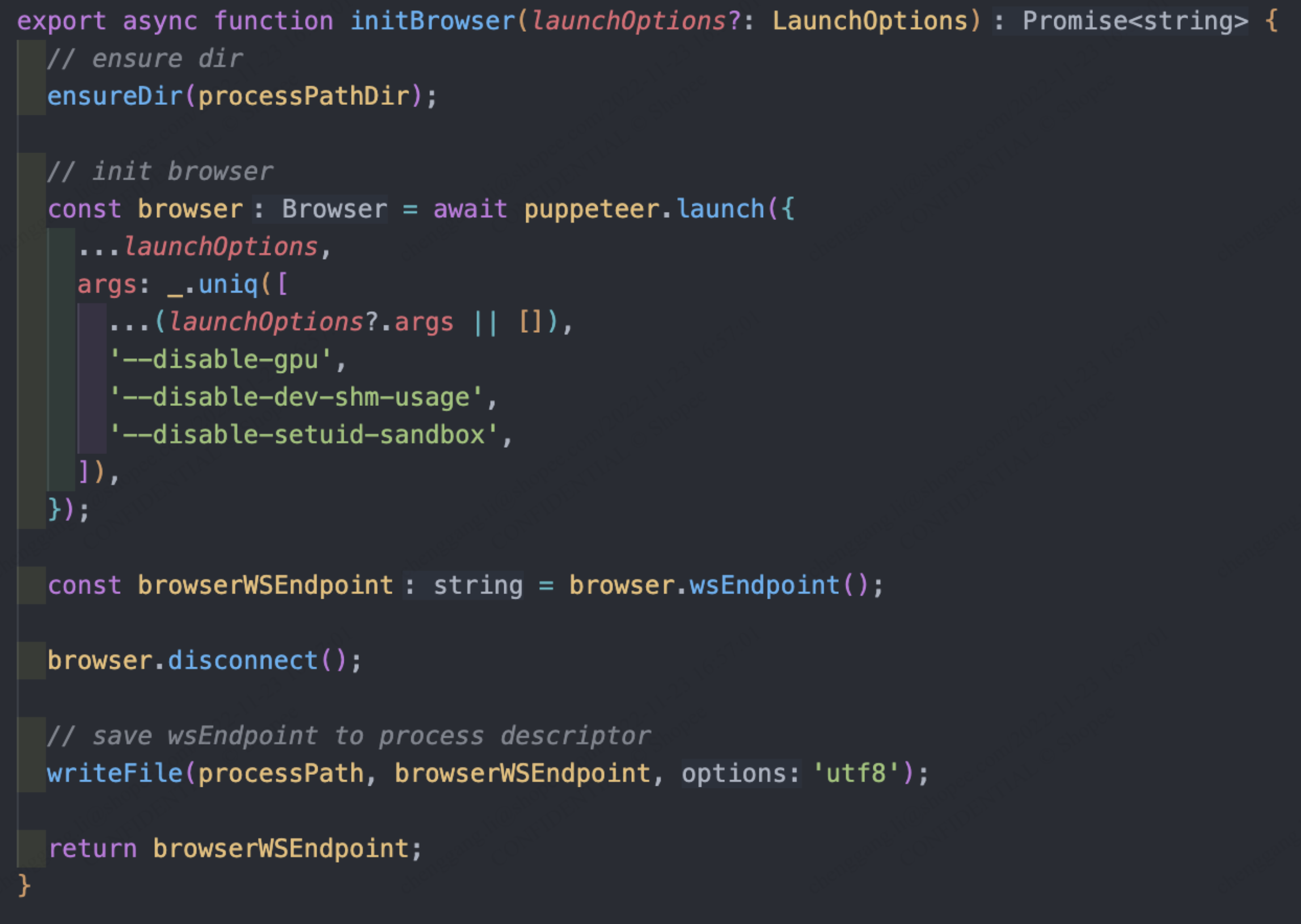
Worker 在需要使用到 Puppeteer 启动浏览器渲染页面的时候,不再使用 puppeteer.launch() 启动浏览器,而是通过 lib/puppeteer 提供的 launch 方法获取 browser 对象。Browser 对象就是 Puppeteer 的 Browser 对象,之后的其他写法与之前保持一致,需要注意的是,使用完浏览器,我们只需要调用 page.close() 关闭页面防止内存泄漏即可,而不再需要关闭浏览器。
lib/puppeteer 内部会读取 ./tmp/puppeteer 文件中的 WebSocket 地址,使用 puppeteer.connect 连接上已经启动的 Chrome 浏览器,提供给外部使用。需要注意的是,为了防止 Worker 错误的调用了 close 方法,而导致持久化的 Chrome 浏览器被关闭,这里会复写 close 方法,实现改为与浏览器断开连接( browser.disconnect() )。

至此,我们实现了单机的 Puppeteer 持久化。
本质原理类似我们在 PC 上使用浏览器一样,会一直启动 Chrome 浏览器,当我们需要访问一个页面的时候,是新建一个 Tab(在 Puppeteer 中,就是一个 Page),访问完一个页面,我们不会关闭掉浏览器,而是只会关掉当前 Tab。
这个设计也有助于未来我们进行横向拓展,当前是每台机器会有一个浏览器保持运行,未来可以单独提供一个浏览器集群,通过动态分配 browserWSEndpoint 的形式,实现动态扩展爬虫的能力。

