浏览器指纹介绍
简单来说它是用于定位和识别浏览用户的,它要尽可能的具有唯一性。
应用场景
- 进行广告推荐。当你在网站上浏览某个商品时,即便是没有进行登录操作。再用同台电脑访问其他网站的时候可能会发现很多同类商品的广告。
- 协助识别同一设备。主要用来打击爬虫所应用的那些方向,例如水军,大量爬取数据,抢购,薅羊毛,客户端欺诈等等。
- 收集用户信息形成长期数据记录,可能侵犯到隐私。
浏览器指纹的发展
- 第一代浏览器指纹是有状态的,也就是cookie,storage以及IndexedDB等各个维度的客户端存储,其优点在于方便实现,识别精准。缺点在于基本存储维度较多但用户仍能手动清理。
- 第二代算是真正有了浏览器指纹的概念,主要是通过不断的增加检测浏览器的特征值从而让用户更具有区分度,例如 UA、webapi特征,浏览器插件信息,另外还会有一些操作系统以及硬件信息来实现初步的跨浏览器指纹识别等,这也是目前实现浏览器特征识别最主要的方式,也是本文将重点介绍的。
- 最新一代的识别技术是会聚焦在人的行为习惯来建立特征值甚至模型,不过这是未来识别的发展方向,目前落地难度较大且不主流,暂不做讨论。
应用图
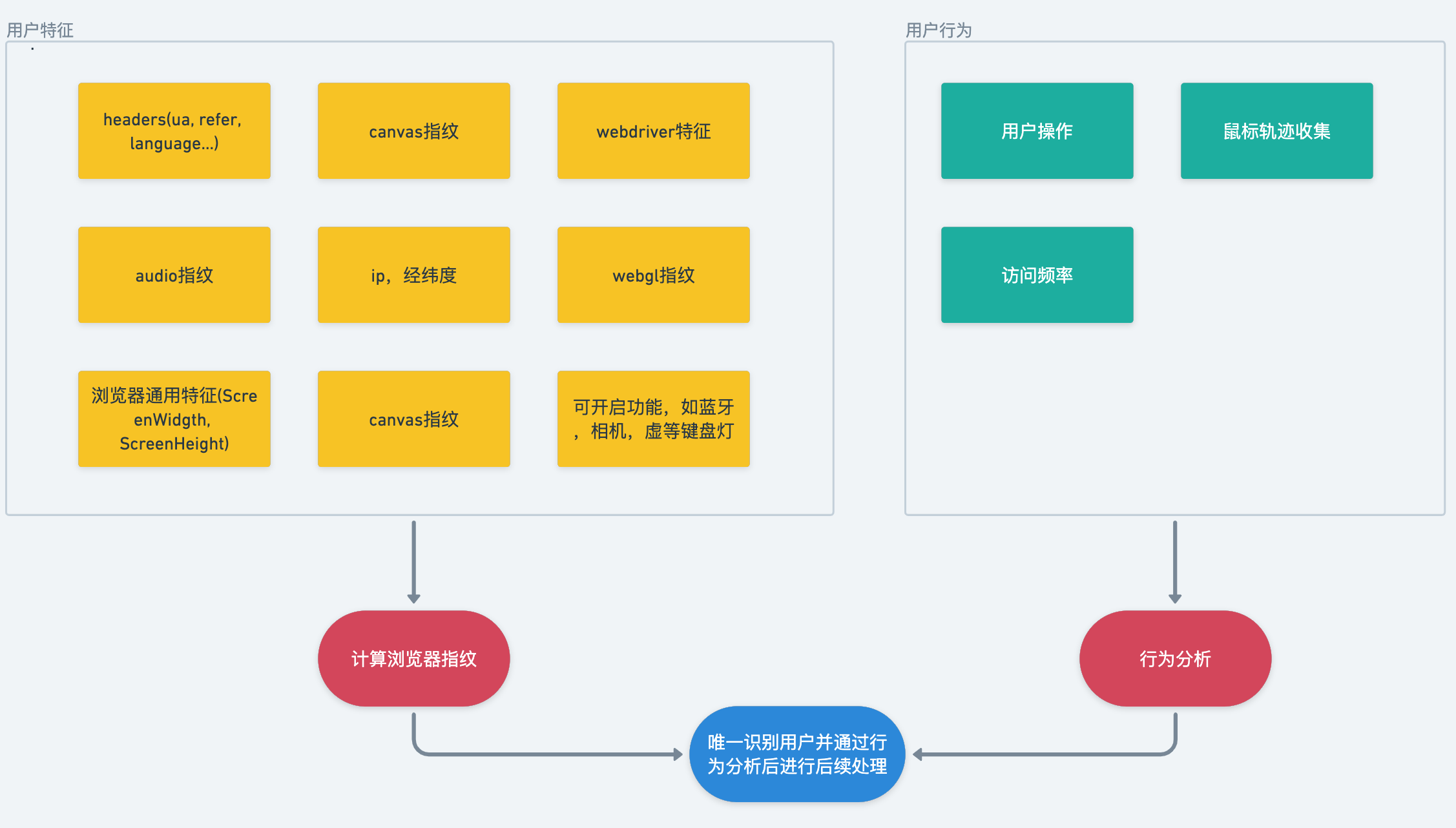
指纹检测与修改
一般对于服务端来说,其识别爬虫的手段主要是三个方面:
- 对请求的headers进行检测,找到它和浏览器发出的请求的区别并加以识别,该检测是最初阶的检测方式。即对UA等headers属性进行检测,主要特征包括UA, accept, content language, encoding等,这些修改起来很简单,本文不做详述。
- 利用指纹和特征检测区分headless与真实用户,这里主要涉及到的是headless检测或者webdriver的检测,找到其与正常浏览器的区别。
- 利用指纹提取对多个请求进行归并处理以期识别出爬虫。
headless检测
该特征检测主要用于让服务器误认为headless为真实用户浏览器的请求。
正常用户浏览器和headless的区别
参考网站:https://arh.antoinevastel.com/bots/areyouheadless
当我们正常用chrome访问该网站时,它准确的识别到了这不是headless
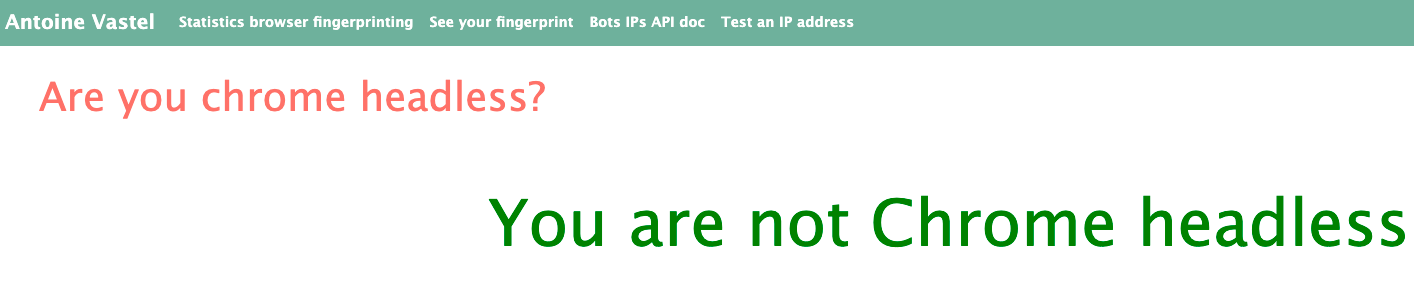
当用headless访问时它能识别到这是headless

在作者的这篇文章中展示了这个网站检测headless的原理,一共是做了6处检测:
- 对ua的正则检测
if (/HeadlessChrome/.test(window.navigator.userAgent)) {
console.log("Chrome headless detected");
}正常浏览是
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
headless的是
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/106.0.5249.0 Safari/537.36
- 对webdriver的检测,正常浏览是false,用webdriver启动是true
if(navigator.webdriver) {
console.log("Chrome headless detected");
}- 对chrome的检测,当浏览器是chrome时,正常浏览window.chrome是一个object, headless时是null
// isChrome is true if the browser is Chrome, Chromium or Opera
if(isChrome && !window.chrome) {
console.log("Chrome headless detected");
}- 对权限的检测,正常浏览时Notification.permission是default,headless是denied,且permissionStatus.state是prompt
navigator.permissions.query({name:'notifications'}).then(function(permissionStatus) {
if(Notification.permission === 'denied' && permissionStatus.state === 'prompt') {
console.log('This is Chrome headless')
} else {
console.log('This is not Chrome headless')
}
});- 对插件数量的检测,这个指标就不是很准,只能说插件数量不为0时,对模拟的程度是有正向的影响的。
if(navigator.plugins.length === 0) {
console.log("It may be Chrome headless");
}- 对语言的检测,如果为空就肯定是headless
if(navigator.languages === "") {
console.log("Chrome headless detected");
}综上,只要我们修改这几处属性,就能过掉这个网站的headless的检测。这就是过headless检测的原理。
更多的通用特征检测
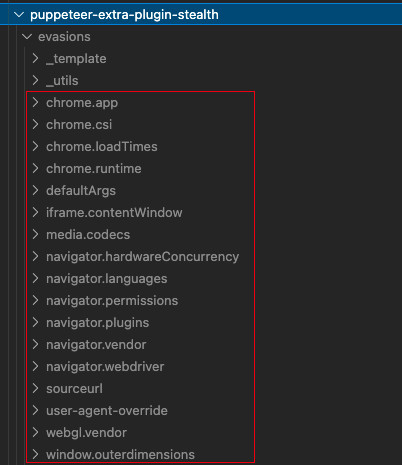
在明白如何通过headless的检测后,实际上网上也已经有很多人总结了一些常见的特征检测,这些特征检测属于既能直接高效的区分真实浏览器和机器人,又能最大程度的不伤害到用户,比如这个插件puppeteer-extra-plugin-stealth就修改了常见的headless检测点:
通过阅读源码可以看出,它对如下的检测点都做了修改。
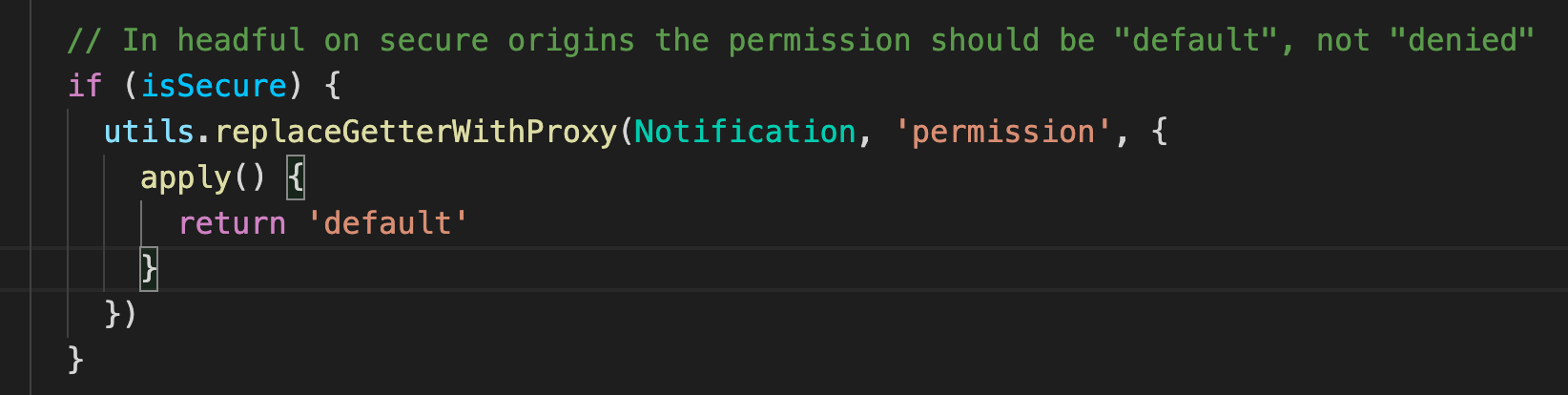
例如在navigator.permissions特征中,该插件就做出了如下修改
不过这类插件的通病是在没什么名气的时候比较好用,一旦渐渐有了名气,各大服务商就会针对该插件新增特殊的检测点,这个时候就需要自己根据特定情况做出修改。不过这个插件已经能过绝大部分的headless检测了(比如阿里滑块的环境检测),今后若是遇到别的检测点,我们可以基于此做特定的修改。
google系验证码的注意事项
在进行调研的时候发现google V2的验证码在我用真实浏览器的时候不会触发更高级别的风控,如下验证只要点击一次就过掉了
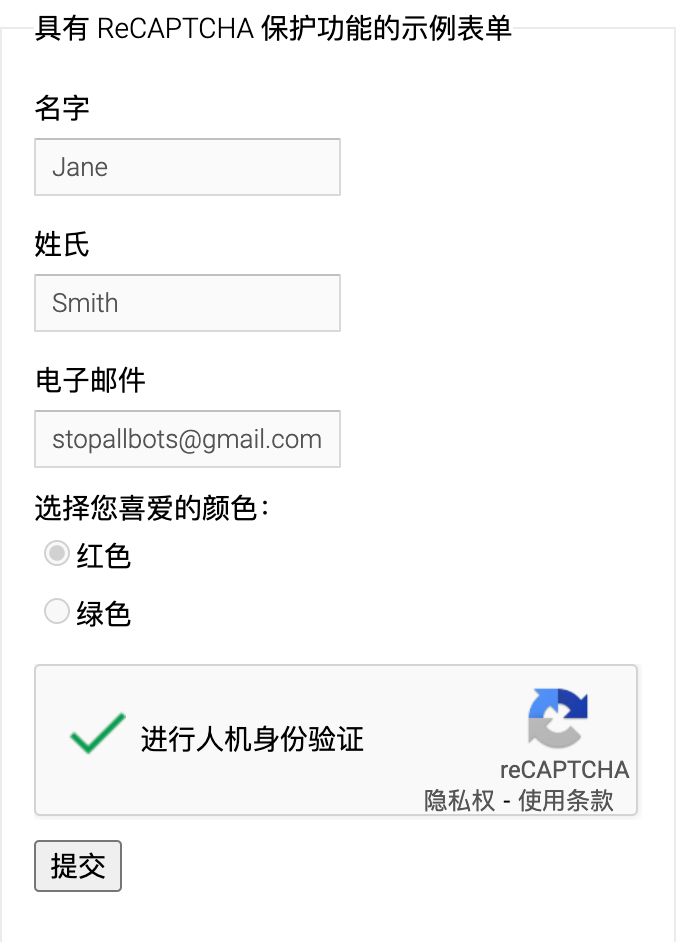
但是在用puppeteer启动浏览器的时候却发现触发了九宫格图片的风控,
也就是触发了更高级别的风控。
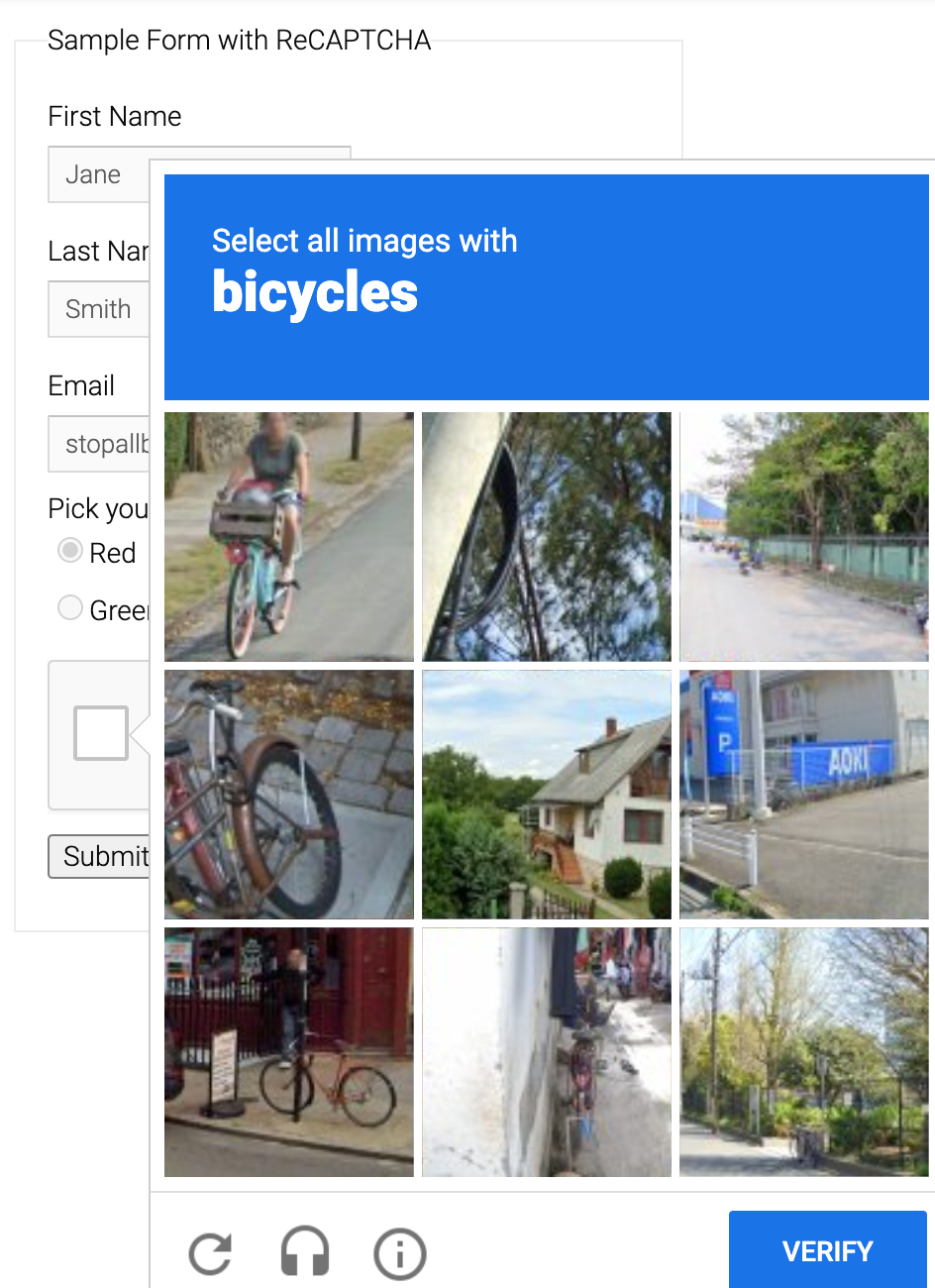
刚开始会理所当然的怀疑是不是检测了某些特征点,但是实际上这是因为google验证码除了检测浏览器特征外还用了某些其他场外信息,例如将 cookie 保持活动状态9天以上(需要通过浏览 Google 资源相关的网站,参考文章),这也就是说即便你用一个真实浏览器,但是没有相关活跃的cookie,也仍然会触发更高级别的风控(我用没怎么使用过的firefox实验确实如此),而这就已经不是单纯的浏览器的环境检测了。
指纹获取计算及随机
在突破了headless的检测后,意味着你可以利用自动化工具缓慢的获得数据了,但是在大批量数据的获取需求下,还需要随机生成浏览器指纹,让服务器不那么好定位到你一个浏览器指纹短时间内访问了成百上千次数据。如果不对自己的浏览器指纹随机化,那么服务端会根据提取到的很多的指纹信息然后将你的浏览器锁定在一个很小的范围内甚至唯一定位到。
特征获取
特征获取中一个很重要的信息来源就是Navigator对象,它包含了当前浏览器的很多数据信息,经常用于检测浏览器和操作系统版本,其检测也没有统一标准,但是一般包含 navigator.cookieEnabled、navigator.plugins、 navigator.platform、navigator.appVersion、navigator.appName 等,其中最重要的是 navigator.user-Agent,囊括了浏览器的大量信息。
其次通过 Screen 对象可以获取用户的屏幕数据,即 Screen.width、Screen.height、 Screen.depth、Screen.availtop、Screen.availleft 等,单位一般以像素计算。JavaScrip对比其他方式获得到的信息量较多,是最常用的浏览器特征获取途径。
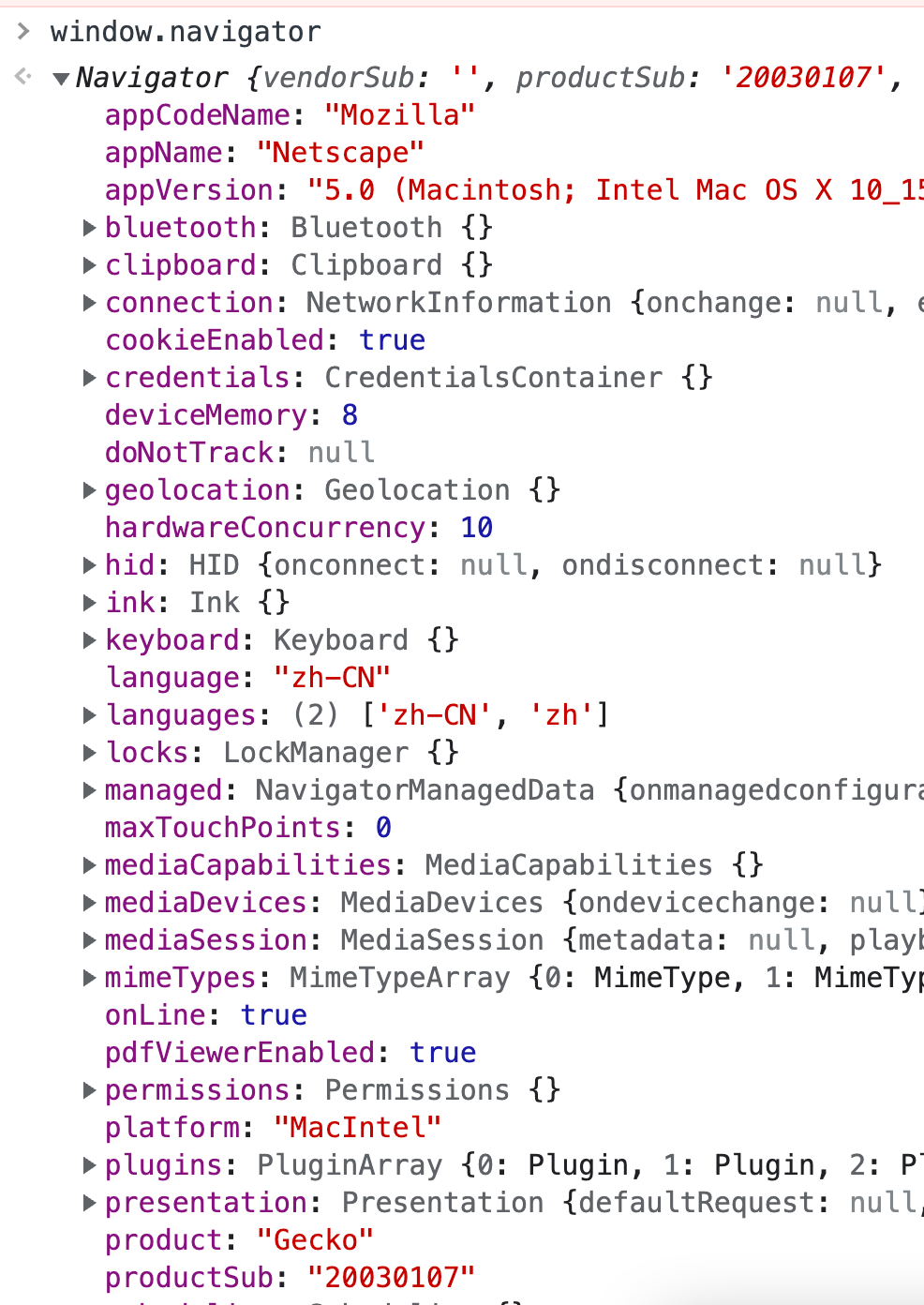
特征获取示例网站:https://gongjux.com/fingerprint/和https://amiunique.org/fp
用无痕模式访问该网站,该网站提取了如下信息,每次访问都是这个结果,这意味着如果网站管理人员将其中容易变化的如ip,localtime等字段剔除,用剩下其他的不易变化且重复率不会太高的字段组合在一起并进行摘要运算得到一个固定位数的串,该串就可以作为我这个浏览器的指纹,要是该指纹有任何异常行为,管理人员就可以直接封杀该指纹。当然,实际上的指纹计算可能会纳入更多特征进行计算,这里只是举一个简单计算指纹的例子。
从另一个参考网站可以看到,一个正常的个人浏览器的某些字段重复率是很低的,如下面的UA,canvas等。事实上,大部分真实的指纹计算中也确实会把这些『比较好』的字段的值纳入计算当中。(所谓的比较好就是既能最大程度区分用户,又能不伤害真实用户的字段)
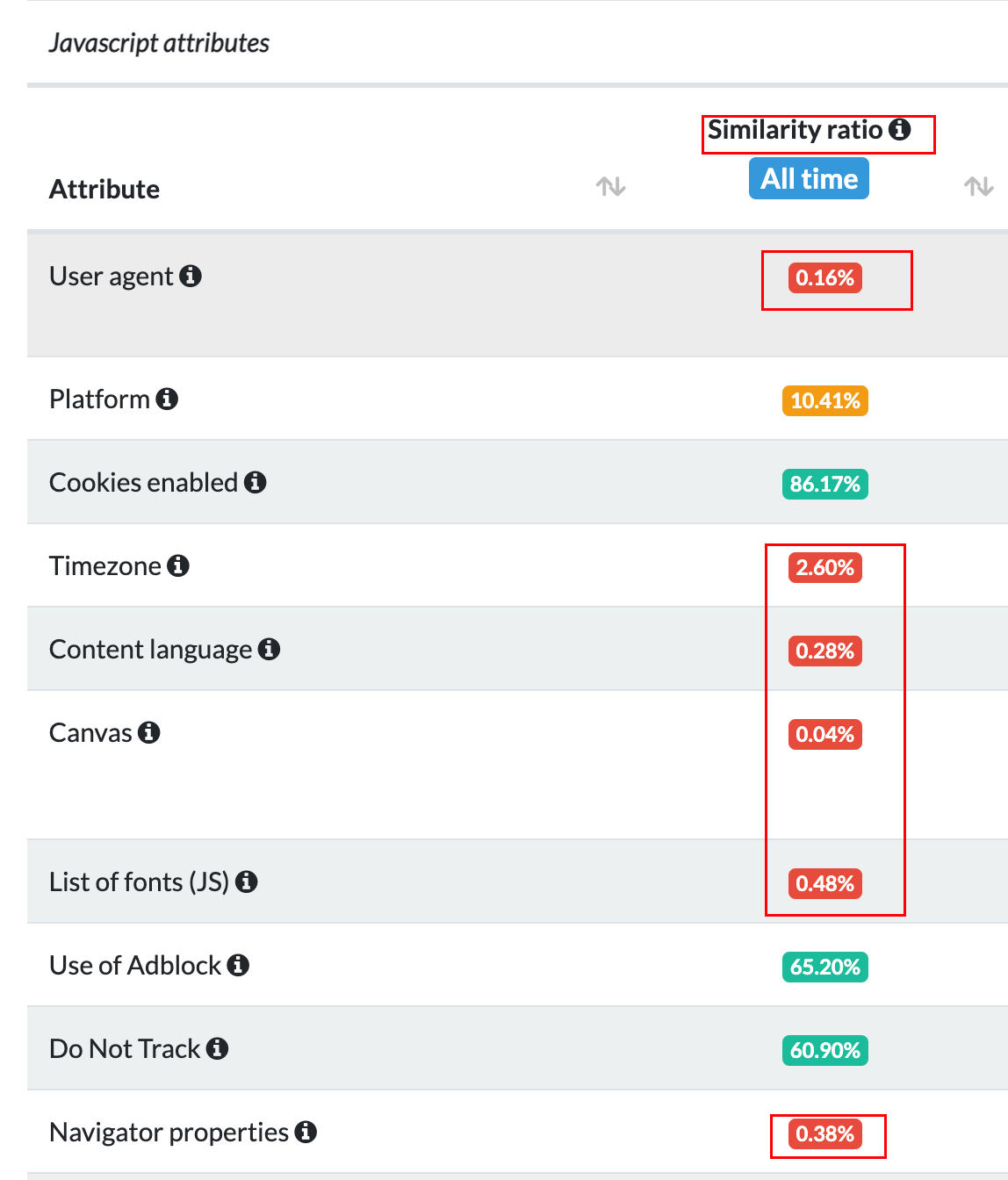
指纹随机
在排除了一些容易变化或重复率太高等这些不太好的字段后,我们可以找到如下这几个重要特征来进行介绍和修改
canvas特征
canvas指纹介绍
canvas是一种在网页上绘制2D和动画的技术。通过html5的canvas接口,在网页上绘制一个隐藏的画布图像。不同的图形处理引擎、不同的图片导出选项、不同的默认压缩级别等。在像素级别来看,操作系统各自使用了不同的设置和算法来进行抗锯齿和子像素渲染操作。
计算机程序通过计算这张图片数据的哈希值,能够识别不同硬件设备渲染结果的细微区别。通过这种方式,技术上就能够通过计算用户设备的canvas指纹来标识用户。
需要注意的是,如果用户的设备,操作系统,浏览器都一样的话,计算出来的canvas指纹是一样的。
canvas指纹计算
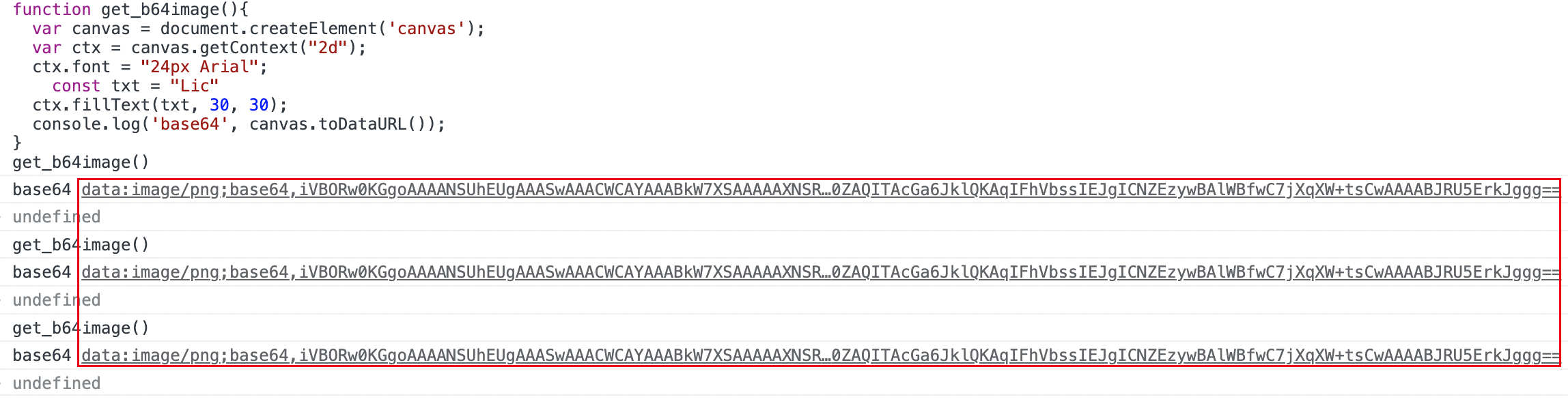
计算过程比较简单,就是自己设置一下参数,绘制一张图,得到其base64编码,最后还需要对其进行摘要得到一个串,这就是一个简单的canvas指纹算法了,可以想见同一个设备这样计算出来的值都是一样的。代码如下:
function get_b64image(){
var canvas = document.createElement('canvas');
var ctx = canvas.getContext("2d");
ctx.font = "24px Arial";
const txt = "Lic"
ctx.fillText(txt, 30, 30);
console.log('base64', canvas.toDataURL());
}
get_b64image()重复调用的话其实得到的图片b64值是一样的,图片的样子肯定也是一样的。
canvas指纹修改
修改的话思路就是:
- 拿到所有用于绘图的api
- 设计一个噪声函数,用于随机更改偏移量
- hook所有用于绘图的api并添加噪声函数
于是就有了如下代码:
var inject = function () {
// 1. 拿到所有用于绘图的api
const toBlob = HTMLCanvasElement.prototype.toBlob;
const toDataURL = HTMLCanvasElement.prototype.toDataURL;
const getImageData = CanvasRenderingContext2D.prototype.getImageData;
// 2. 设计一个噪声函数,用于随机更改偏移量
var noisify = function (canvas, context) {
const shift = {
r: Math.floor(Math.random() * 10) - 5,
g: Math.floor(Math.random() * 10) - 5,
b: Math.floor(Math.random() * 10) - 5,
a: Math.floor(Math.random() * 10) - 5,
};
const width = canvas.width,
height = canvas.height;
const imageData = getImageData.apply(context, [0, 0, width, height]);
for (let i = 0; i < height; i++) {
for (let j = 0; j < width; j++) {
const n = i * (width * 4) + j * 4;
imageData.data[n + 0] = imageData.data[n + 0] + shift.r;
imageData.data[n + 1] = imageData.data[n + 1] + shift.g;
imageData.data[n + 2] = imageData.data[n + 2] + shift.b;
imageData.data[n + 3] = imageData.data[n + 3] + shift.a;
}
}
window.top.postMessage("canvas-fingerprint-defender-alert", "*");
context.putImageData(imageData, 0, 0);
};
//3. hook所有用于绘图的api并添加噪声函数
Object.defineProperty(HTMLCanvasElement.prototype, "toBlob", {
value: function () {
noisify(this, this.getContext("2d"));
return toBlob.apply(this, arguments);
},
});
Object.defineProperty(HTMLCanvasElement.prototype, "toDataURL", {
value: function () {
noisify(this, this.getContext("2d"));
return toDataURL.apply(this, arguments);
},
});
Object.defineProperty(CanvasRenderingContext2D.prototype, "getImageData", {
value: function () {
noisify(this.canvas, this);
return getImageData.apply(this, arguments);
},
});
document.documentElement.dataset.cbscriptallow = true;
};在调用该js函数后再执行绘图方法可以看到每次产生的b64值都不一样了
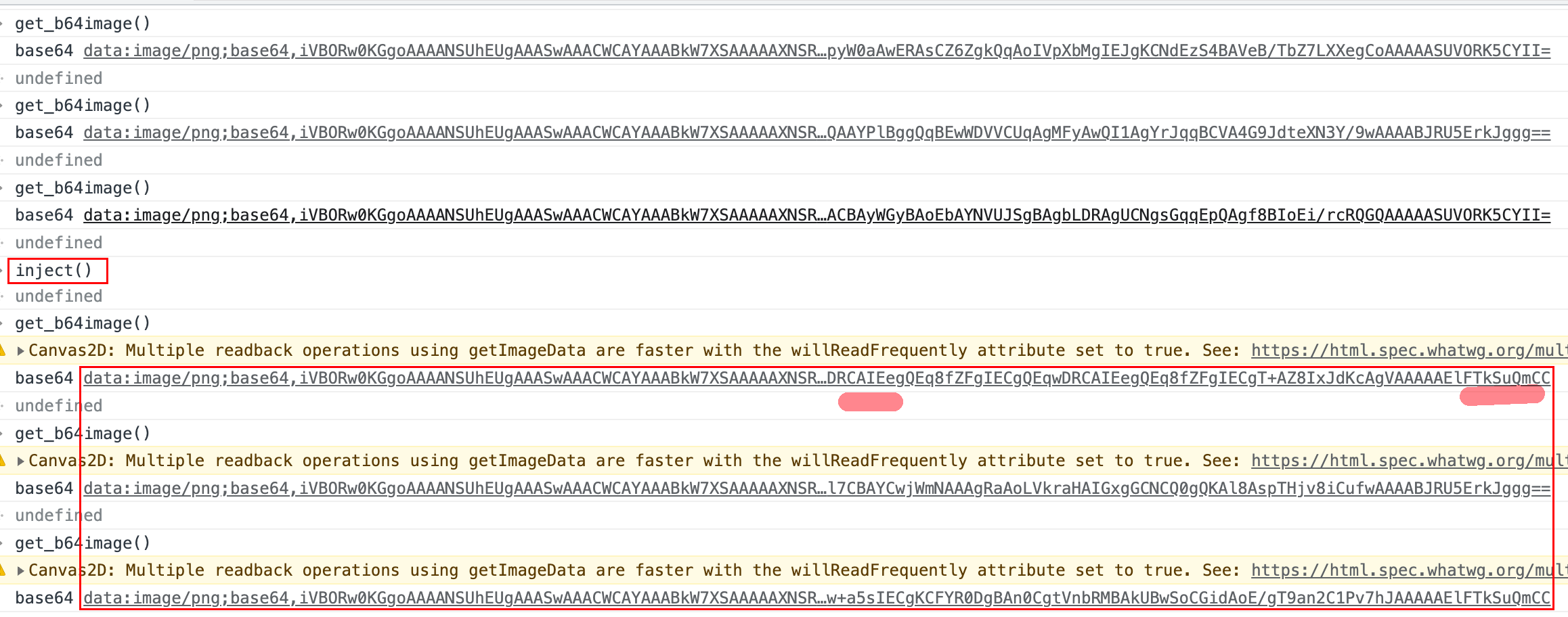
从生成的图像来看,肉眼是无法分辨这三张图的区别的,因为它只有像素级别的改变

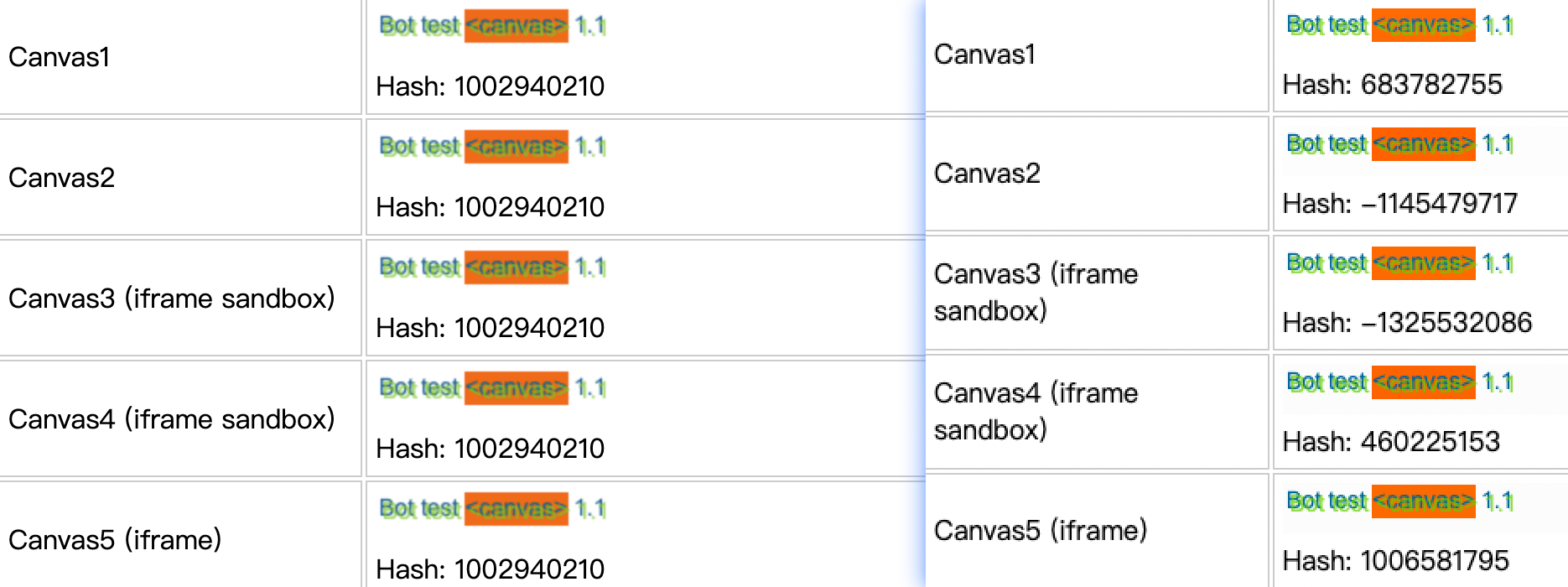
从检测网站上(https://bot.sannysoft.com/)也可以看到,该网站会在不同场景调用五次绘图,左边是正常浏览器的访问,右边是随机指纹后访问。可以看到其每次调用得到的hash都不一样。
audio特征
audio指纹介绍
AudioContext指纹(也被称作“音频指纹”)是设备音频栈的哈希衍生值。
AudioContext指纹原理大致如下:
方法一:生成音频信息流(三角波),对其进行FFT变换,计算SHA值作为指纹,音频输出到音频设备之前进行清除,用户毫无察觉。
方法二:生成音频信息流(正弦波),进行动态压缩处理,计算MD5值。
有兴趣的可以看看这篇论文:https://scholarworks.uno.edu/cgi/viewcontent.cgi?article=4089&context=td
audio指纹生成
audio指纹生成代码,由于音频本身制作也比较复杂,所以下面的代码看起来也很复杂,整个步骤简单来说就是:
- 获取AudioContext
- 用AudioContext的startRendering方法生成音频
- 获取该音频0通道的部分值经过处理得到指纹
var each = function(obj, iterator) {
if (Array.prototype.forEach && obj.forEach === Array.prototype.forEach) {
obj.forEach(iterator)
} else if (obj.length === +obj.length) {
for (var i = 0, l = obj.length; i < l; i++) {
iterator(obj[i], i, obj)
}
} else {
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
iterator(obj[key], key, obj)
}
}
}
}
var AudioContext = window.OfflineAudioContext || window.webkitOfflineAudioContext
// 1. 获取AudioContext
var context = new AudioContext(1, 44100, 44100)
var oscillator = context.createOscillator()
oscillator.type = 'triangle'
oscillator.frequency.setValueAtTime(10000, context.currentTime)
var compressor = context.createDynamicsCompressor()
each([
['threshold', -50],
['knee', 40],
['ratio', 12],
['reduction', -20],
['attack', 0],
['release', 0.25]
], function (item) {
if (compressor[item[0]] !== undefined && typeof compressor[item[0]].setValueAtTime === 'function') {
compressor[item[0]].setValueAtTime(item[1], context.currentTime)
}
})
oscillator.connect(compressor)
compressor.connect(context.destination)
oscillator.start(0)
// 2.用AudioContext的startRendering方法生成音频
context.startRendering()
var audioTimeoutId = setTimeout(function () {
console.warn('Audio fingerprint timed out. Please report bug at https://github.com/Valve/fingerprintjs2 with your user agent: "' + navigator.userAgent + '".')
context.oncomplete = function () { }
context = null
return done('audioTimeout')
}, 100)
context.oncomplete = function (event) {
var fingerprint
try {
clearTimeout(audioTimeoutId)
// 3. 获取该音频0通道的部分值经过处理得到指纹
fingerprint = event.renderedBuffer.getChannelData(0)
.slice(4500, 5000)
.reduce(function (acc, val) { return acc + Math.abs(val) }, 0)
.toString()
oscillator.disconnect()
compressor.disconnect()
} catch (error) {
console.log(error)
return
}
console.log(fingerprint)
}
audio指纹修改
其实这里可以看到有很多api都可以拿来hook并修改,我这里选的是OfflineAudioContext这个构造函数,思路就是:
- 保存原来的OfflineAudioContext
- 新建一个OfflineAudioContext,其构造函数部分的参数随机修改,然后返回
var inject = function () {
// 保存原来的OfflineAudioContext
const originalOfflineAudioContext = window.OfflineAudioContext;
// 新建一个OfflineAudioContext,其构造函数部分的参数随机修改,然后返回
let NewOfflineAudioContext = function (numberOfChannels, length, sampleRate) {
second = Math.floor(Math.random() * 100000);
third = Math.floor(Math.random() * 100000);
const offlineAudioContext = new originalOfflineAudioContext(1, second, third);
return offlineAudioContext;
}
Object.defineProperty(window, 'OfflineAudioContext', {
value: NewOfflineAudioContext,
writable: true,
configurable: true,
});
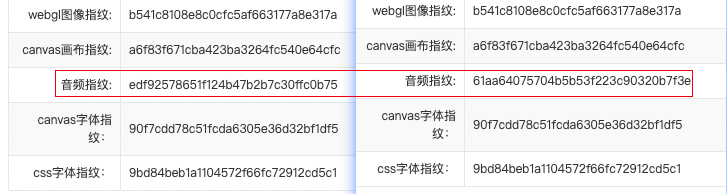
};这样的话就可以看到音频指纹已经被修改了
webgl特征
webgl指纹介绍
webGL是一种在浏览器上绘制3D图形的技术。网站可以通过该技术来识别用户的硬件设备指纹,主要的指纹信息有如下两种:
WebGL Report Hash——完整的WebGL浏览器报告表是可获取、可被检测的。通过读取报告中的vendor和renderer信息,可以获取到显卡的供应商和型号信息。
WebGL Image Hash——渲染和转换为哈希值的隐藏3D图像。由于最终结果取决于进行计算的硬件设备,因此此方法会为设备及其驱动程序的不同组合生成唯一值。这种方式为不同的设备组合和驱动程序生成了唯一值。
webgl指纹修改
和上述指纹修改的原理类似,不过要麻烦不少,图省事的话可以直接禁用掉webgl的支持,实现方式就是puppeteer的启动参数加入禁用的选项。类似下面这样
const browser = await puppeteer.launch({
// 前者是禁用webgl,后者是禁用一切3d绘图的api
args: ["--disable-webgl", "--disable-3d-apis"],
});修改前:
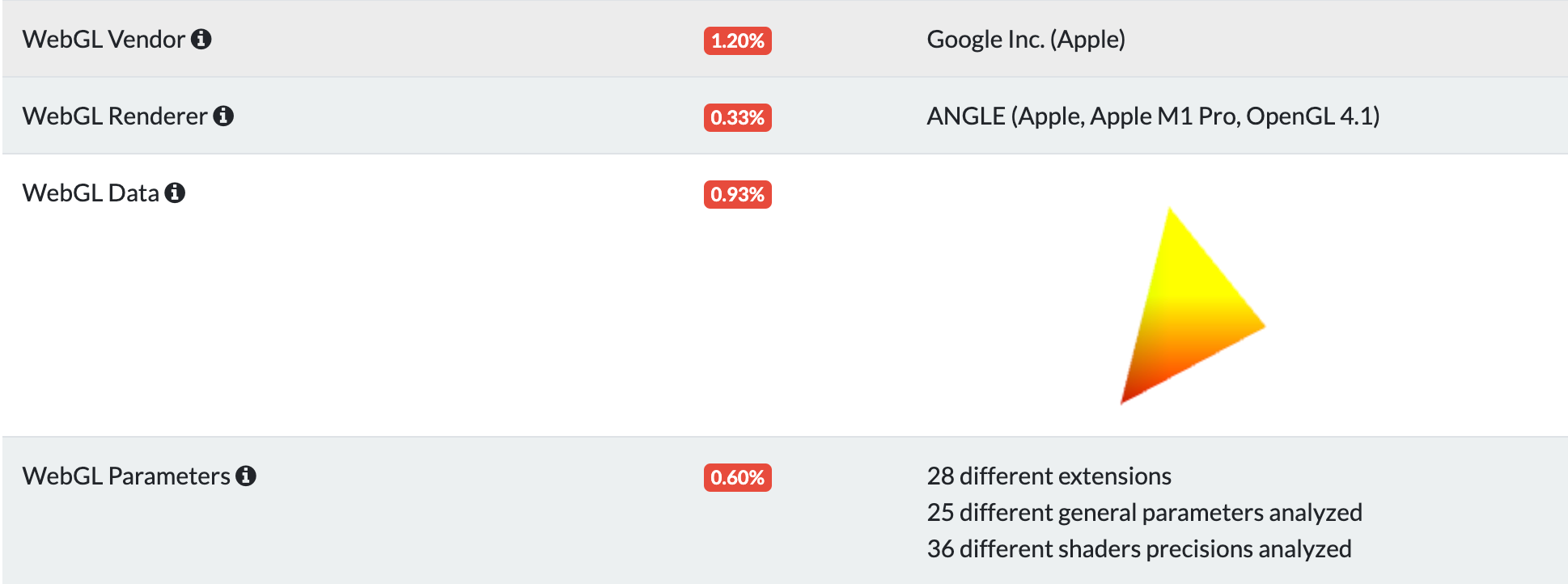
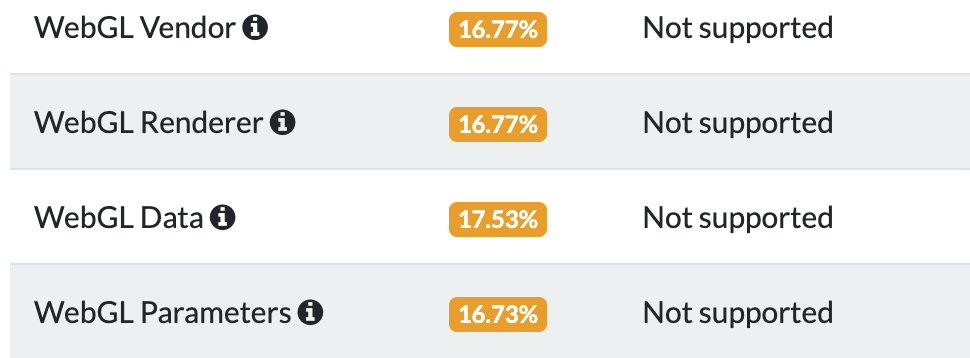
修改后的结果,它会让检测指纹的网站无法得到webgl的信息,从而无法计算指纹。
指纹检测寻找实战
之前提到的那些措施已经可以过掉绝大部分的headless检测和指纹定位了,前面提到的那些网站也都没什么难度,接下来看看检测很严格的网站。
该网站检测非常严格,甚至能检测到你是否隐藏了自己的指纹。
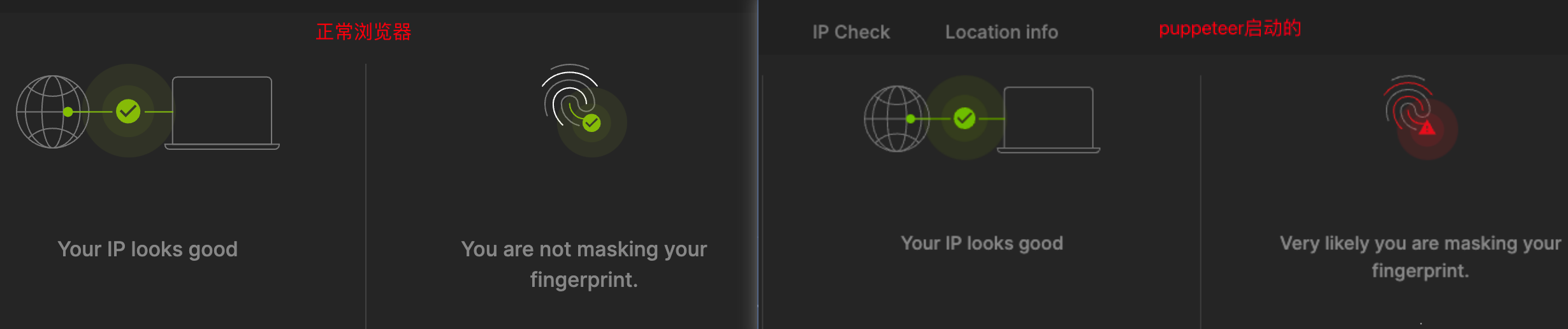
并且用了大量js保护措施,类似这样
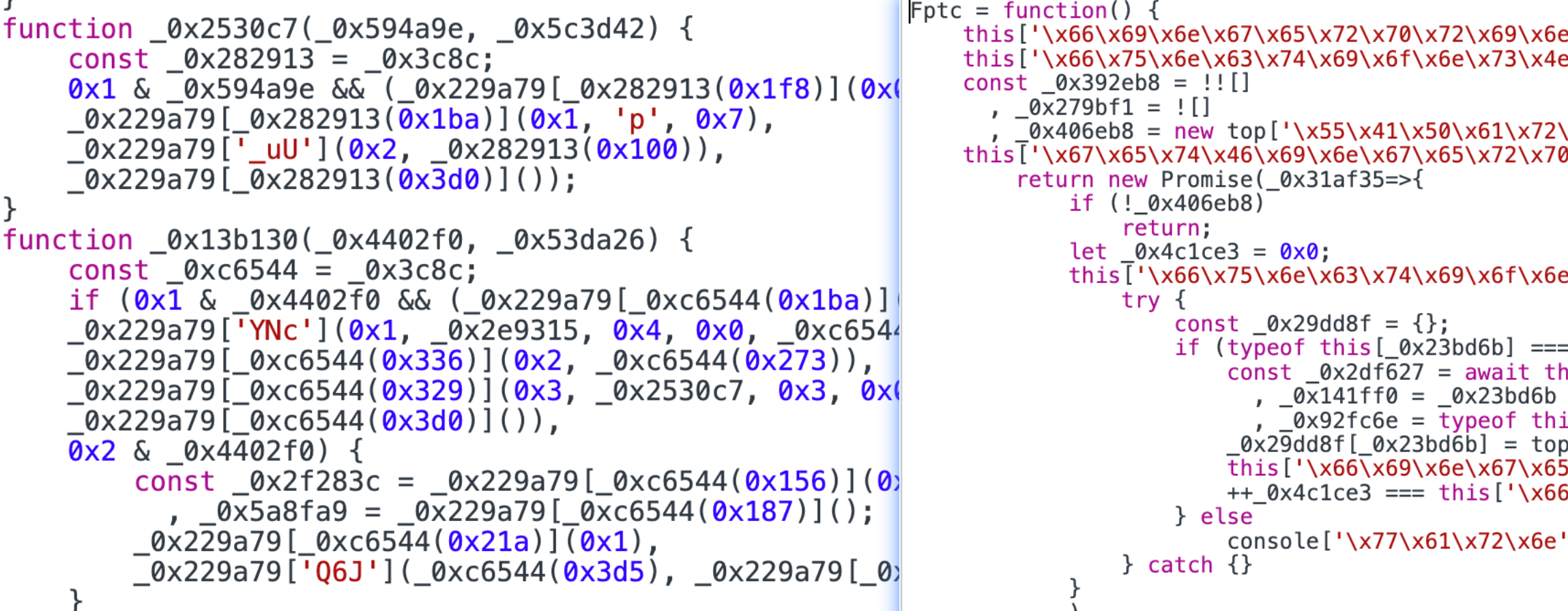
但是由于js的逆向分析不是本文重点,所以忽略寻找过程直接定位到关键值,可以看到正常的浏览器元素4的value是简单的true,而puppeteer启动的是一串修改值,
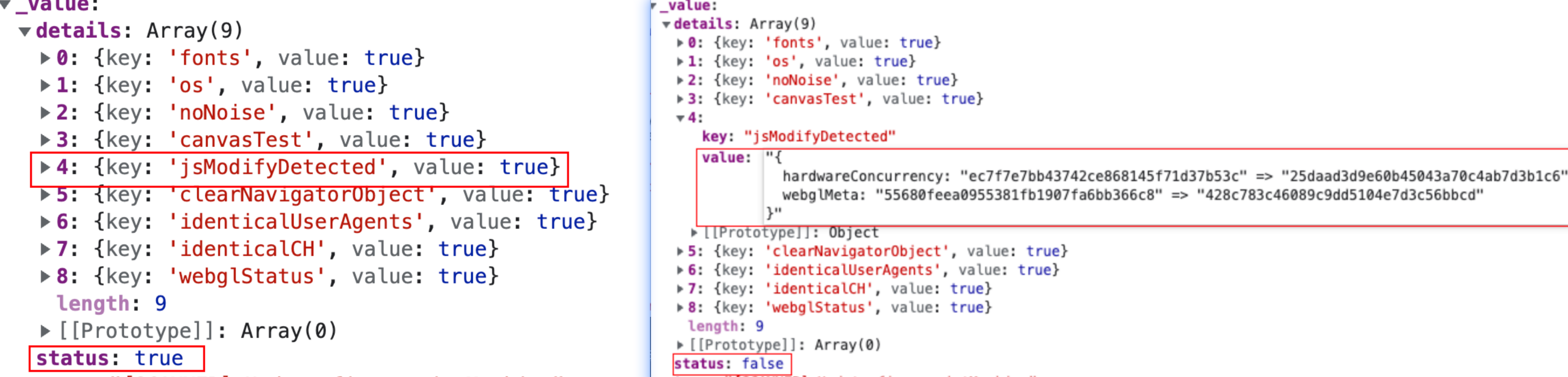
在实战中到这里就可以截止了,因为找到检测点后我们可以应对的措施很多,比如替换js,hook并修改该方法,直接修改这个status值等等,但是我们可以再深入一下去找找它为什么能计算出puppeteer和真实浏览器的区别,于是可以继续往下找就找到了这里,所以其实可以发现它其实用了两种收集的方法,然后做了个对比,由于在puppeteer中我们有随机指纹,所以它两次计算肯定会不一样,只要发现不一致就返回false,而真实浏览器这里计算出来是一致的。
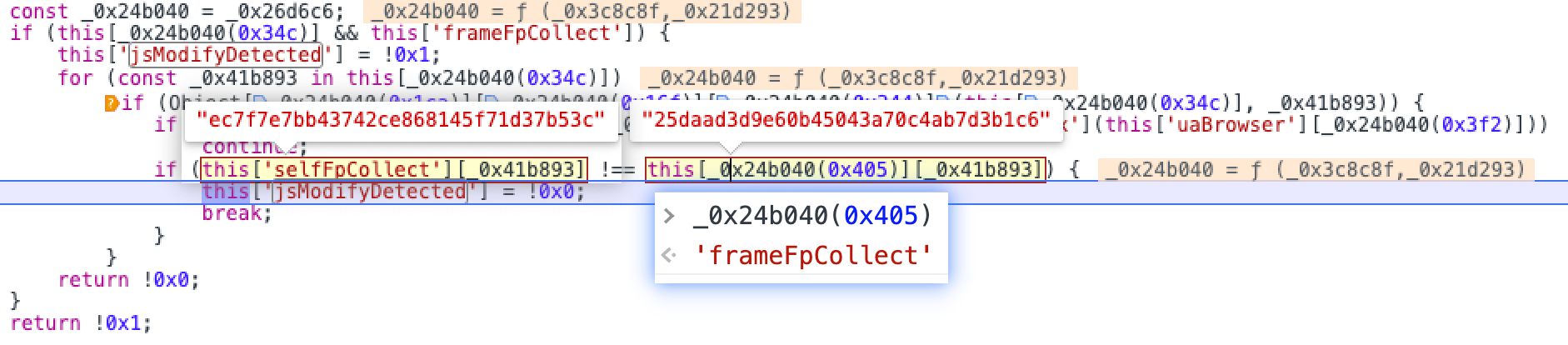
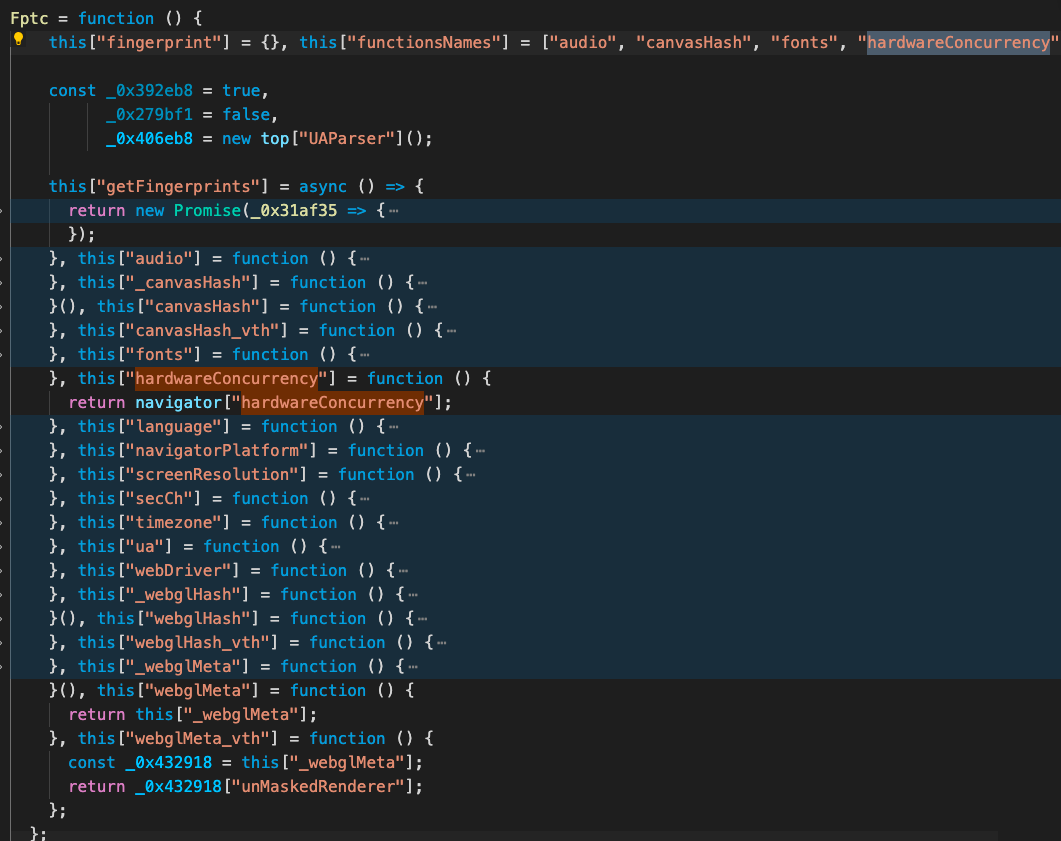
继续往下追就能看到该网站计算指纹的核心代码
总结
利用headers的随机以及上述的webapi和硬件的指纹随机和修改已经能过过掉绝大部分的指纹以及headless的检测了,要是遇到新的检测点也不要慌,解决思路就是:
- 找到所有其访问的监测点(可以利用hook,也可以人肉扫描代码)
- hook住所有检测点,然后:
- 该模拟成正常浏览器就仿照浏览器模拟
- 该修改指纹特征的就要寻找最佳hook点并随机数据
当然,这些hook和代码扫描就要js逆向的一些手段及工具了,这是另外一个难点。

